Overview
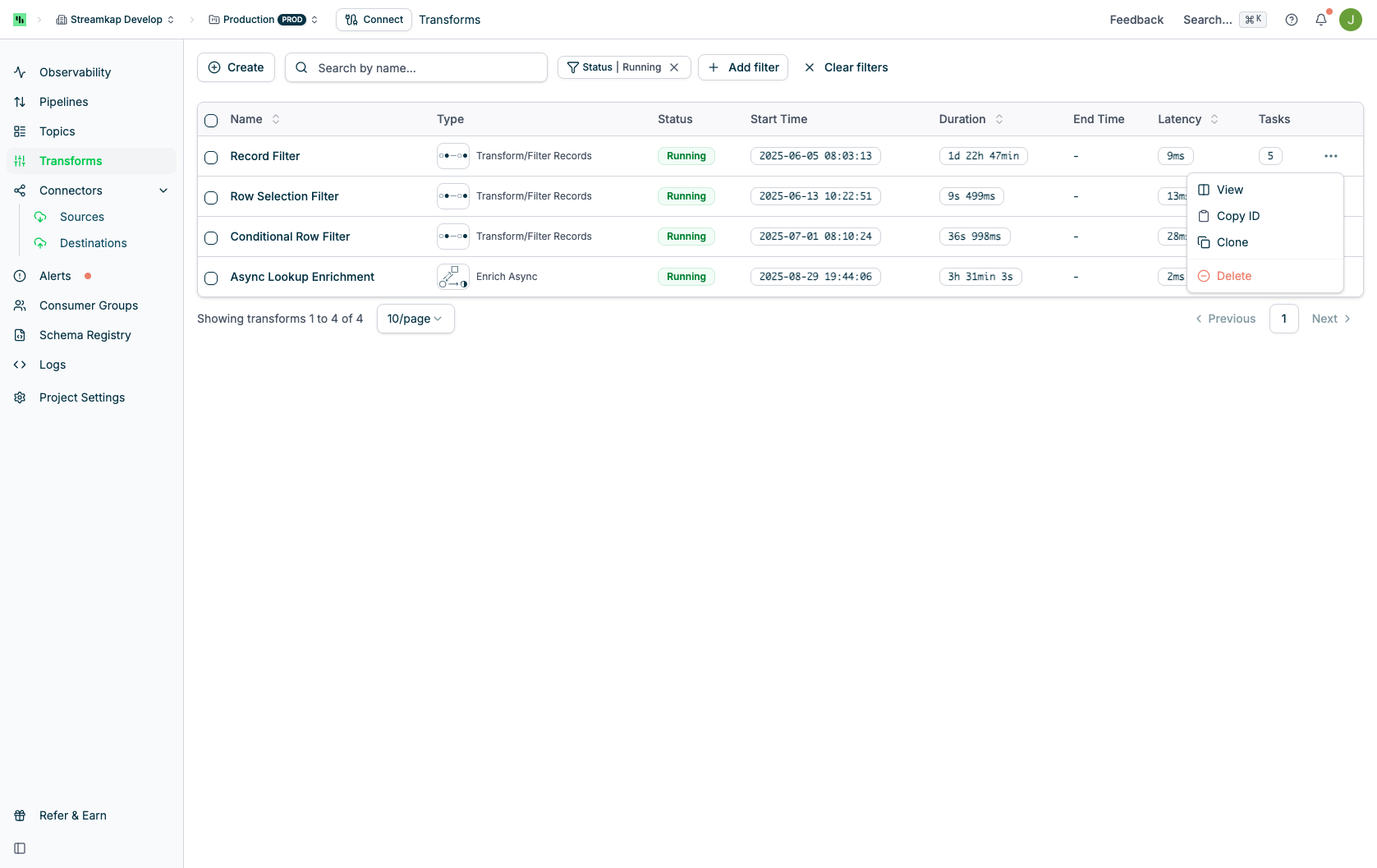
The Transforms page displays all active transforms with their current status and performance metrics:Page Actions
- Create Transform: Launch the transform creation wizard
- Search: Filter transforms by name
- Refresh: Reload the transforms list
Transforms Table
The table displays all transforms with the following columns:- Name: User-defined transform name (click to view details)
- Type: Transform type (e.g., “Transform/Filter Records”, “Aggregate”, “Join”, “Enrich”)
- Status: Current transform job status
RUNNING: Transform is actively processing recordsRESTARTING: Transform is restarting due to failure or configuration changeFAILED: Transform has failed and requires attentionUNKNOWN: Status cannot be determined
- Start Time: Timestamp when the current transform job started
- Duration: How long the current job has been running
- End Time: Timestamp when the job ended (for completed/failed transforms)
- Latency: Average time for records to be processed by this transform
- Tasks: Number of parallel tasks executing the transform logic (degree of parallelism)
Row Actions Menu
Click the actions menu (⋮) on any transform row to access:- View: Navigate to transform detail page
- Copy ID: Copy transform UUID to clipboard (useful for API calls and support tickets)
- Clone: Create a copy of this transform with the same configuration
- Delete: Remove the transform (requires confirmation)
Bulk Actions
Select multiple transforms using the checkboxes on the left side of the table to perform actions on multiple transforms at once. When transforms are selected, the bulk actions bar appears at the top of the table.- Clone: Create copies of all selected transforms with “_copy” appended to their names
- Delete: Remove all selected transforms (requires confirmation)
You can select individual transforms or use “Select all X matching transform” to select all transforms in the current view.
Transform Detail Page
Click any transform name to view detailed information across three tabs: Status, Settings, and Implementation.Status Tab
The Status tab displays real-time metrics and output topics:- Status: Current job status (
RUNNING,RESTARTING,FAILED, orUNKNOWN) - Tasks: Number of parallel tasks (degree of parallelism)
- Latency: Average record processing time
- Duration: How long the current job has been running
- Name: User-defined transform name
- Type: Transform type (e.g., “Transform/Filter Records”, “Aggregate”, “Join”)
- Job: Apache Flink job identifier
- Name: Output topic name (click to view topic details)
- Volume: Total data volume written to this topic
- Errors: Number of processing errors
- Written: Total number of records written
Transforms can write to multiple output topics depending on the transform logic and routing rules.
Settings Tab
Configure transform parameters and resource allocation:- Name: Transform display name (editable)
- Tags: Custom tags for organizing transforms
- Language: Transform implementation language. Available options depend on the transform type (JavaScript, Python, or SQL).
- Input Pattern: Regular expression matching input topic names
- Example:
.*\.db_shard.*matches all topics containing “.db_shard.” - Supports standard regex syntax
- Example:
- Output Pattern: Template for output topic names
- Example:
db_users.users_aggregatedcreates a single output topic - Can include variables for dynamic topic creation
- Example:
- Transform Parallelism: Slider to adjust the number of parallel tasks
- Start with 1-5 for most workloads, then scale up based on lag metrics.
- For high-throughput transforms, raise parallelism toward the number of input topic partitions (parallelism above partition count yields no extra throughput).
- Higher parallelism increases throughput but consumes more resources.
Implementation Tab
The Implementation tab contains the transform logic code and testing interface. Transform Code Editor- Write or edit transformation logic in the language selected on the Settings tab (JavaScript, Python, or SQL — depending on the transform type)
- Access to Streamkap transform APIs and utilities
- Syntax highlighting and error detection
- Test transform logic with sample records
- View transformation output before deploying
- Debug transformation errors
Refer to the Transform Types documentation for specific implementation examples and available APIs for each transform type.
Best Practices
- Start with Low Parallelism: Begin at 1-5 for most workloads (or match input partition count for known high-throughput transforms), then scale up based on lag metrics
- Monitor Latency: Watch the latency metric to identify performance bottlenecks
- Use Descriptive Names: Name transforms clearly to indicate their purpose
- Test Before Deploying: Use the Implementation tab testing interface to validate logic
- Handle Errors Gracefully: Implement error handling in transform code to prevent job failures
- Review Output Topics: Regularly check output topic metrics for unexpected errors or volume
- Optimize Input Patterns: Use specific regex patterns to avoid processing unnecessary topics
- Document Transform Logic: Add comments in Implementation tab to explain complex transformations
Troubleshooting
Transform Status Shows RESTARTING
If a transform continuously restarts:- Check Logs: Review transform logs in the Logs page for error messages
- Verify Input Topics: Ensure input pattern matches existing topics
- Test Transform Logic: Use Implementation tab to test with sample data
- Check Resources: Verify project has sufficient resources for the parallelism level
- Review Recent Changes: Revert recent settings or code changes that may have caused the issue
High Latency
If transform latency is increasing:- Increase Parallelism: Scale up the number of tasks in Settings tab
- Optimize Transform Code: Review and optimize JavaScript logic in Implementation tab
- Check Input Lag: Verify input topics don’t have excessive consumer lag
- Review Resource Usage: Ensure project has sufficient CPU and memory
- Partition Input Topics: Increase partitions on input topics for better parallelism
No Output Records
If the transform shows zero written records:- Verify Input Pattern: Ensure regex pattern matches actual topic names
- Check Transform Logic: Confirm logic doesn’t filter out all records
- Review Input Topics: Verify input topics contain data
- Check for Errors: Look at Errors metric and review logs
- Test Implementation: Use Implementation tab testing to validate logic
Related Documentation
- Transform Types - Detailed guides for each transform type (Filter, Aggregate, Join, Enrich)
- Pipelines - How transforms integrate into data pipelines
- Topics - Understanding input and output topics
- Logs - Troubleshooting transform errors
- Projects - Managing project resources for transforms