Overview
The Schema Registry page displays all schema subjects registered in your project: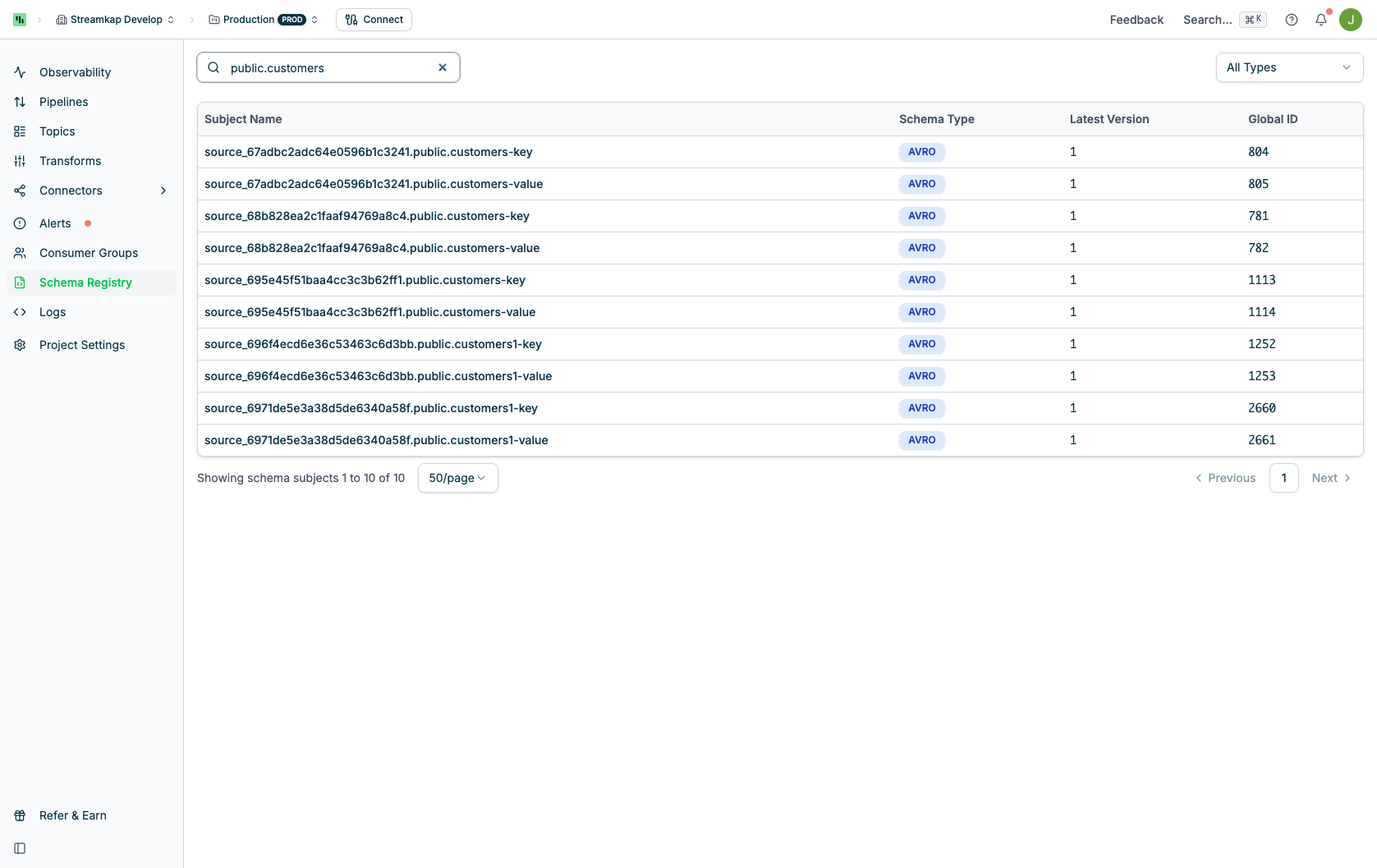
Key Features
- Search Functionality: Filter schemas by subject name using the search bar
- Type Filtering: Filter schemas by type (AVRO, JSON, Protobuf)
- Version Tracking: View and compare different schema versions
- Schema Inspector: Browse schema definitions with syntax highlighting
- Evolution History: Track how schemas change over time
- Global ID Reference: Unique identifier for each schema version
Schema Registry Table
The main table lists all schema subjects with the following columns:- Subject Name: The schema subject identifier
- Click to navigate to the schema detail page
- Typically follows the pattern:
{topic-name}-keyor{topic-name}-value - Format:
source_{id}.{database}.{table}-{key|value}
- Schema Type: The serialization format
AVRO: Apache Avro binary format (most common for CDC)JSON: JSON Schema formatPROTOBUF: Protocol Buffers format
- Latest Version: The current version number of the schema
- Increments with each schema update
- Version 1 indicates the initial schema
- Global ID: Unique identifier across all schemas in the registry
- Used internally by Kafka for schema resolution
- Increments monotonically across all schema versions
Search and Filtering
- Search Bar: Filter schemas by entering part or all of a subject name
- Type Filter: Use the “All Types” dropdown to show only schemas of a specific format
- Pagination: Navigate through schemas with configurable page size (10, 20, 50, or 100 per page)
Subject names ending in
-key define schemas for message keys, while -value subjects define schemas for message payloads.Schema Detail Page
Click any subject name to view detailed information about the schema, including its definition and version history.Schema Overview
The detail page displays key information about the selected schema: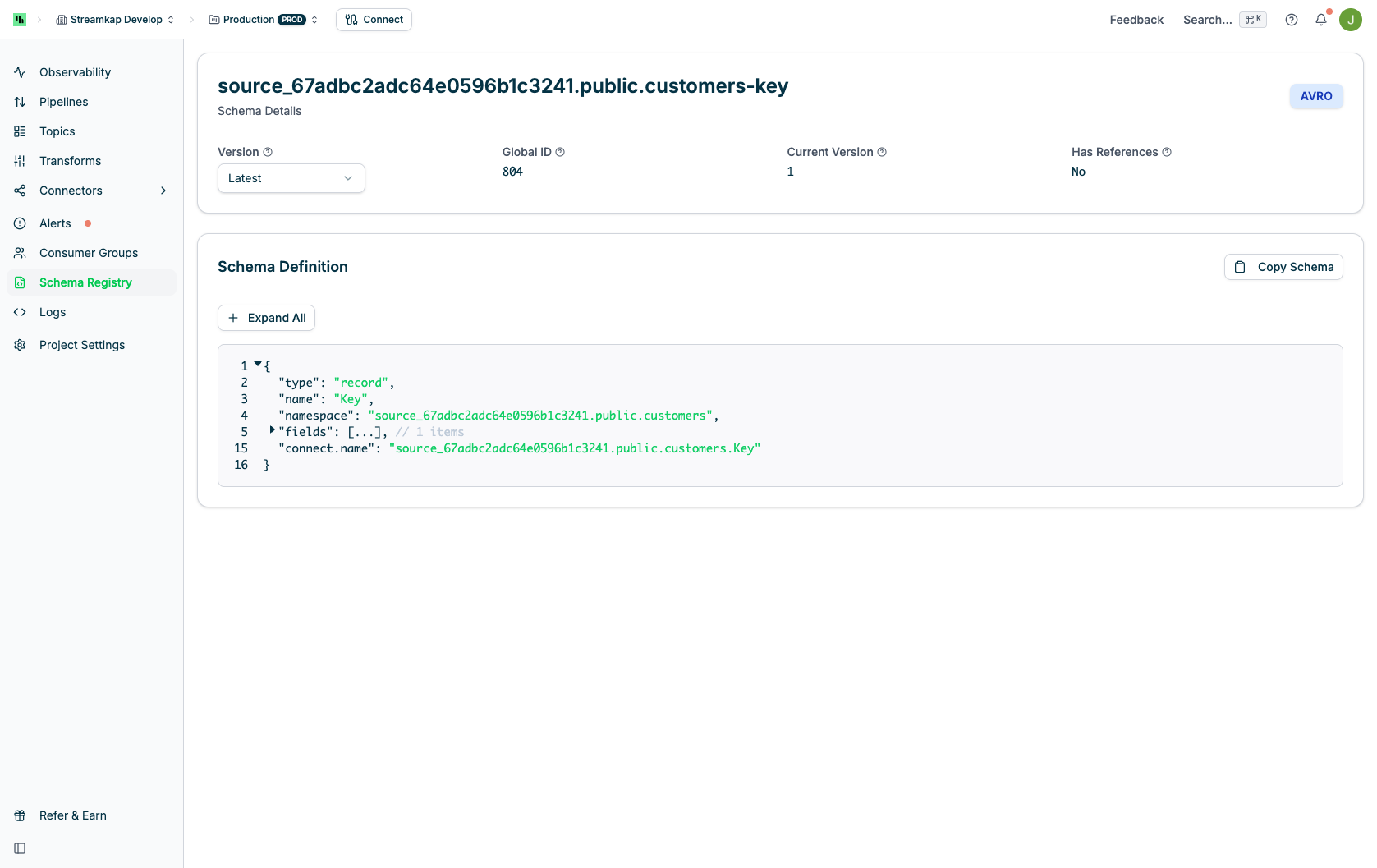
- Schema Type: The serialization format (shown as a badge in the top-right)
- Version Selector: Dropdown to switch between schema versions
- “Latest” shows the most recent version
- Version numbers listed for historical versions
- Global ID: The unique identifier for this schema version in the registry
- Current Version: The version number currently selected
- Has References: Indicates if the schema references other schemas
- “Yes”: Schema imports or references external schema definitions
- “No”: Schema is self-contained with no external dependencies
Schema Definition
The Schema Definition section displays the complete schema structure with interactive viewing options: Features:- Syntax Highlighting: JSON/Avro syntax with color coding
- Line Numbers: Easy reference to specific parts of the schema
- Collapsible Sections: Click arrows to expand/collapse nested fields
- Field Summaries: Collapsed sections show item counts (e.g., ”// 12 items”)
- Copy Schema: Button to copy the entire schema definition to clipboard
- Expand All: Button to expand all collapsed sections at once
AVRO schemas, you’ll typically see:
- type: The schema type (e.g., “record”, “string”, “int”)
- name: The name of the record or field
- namespace: Fully qualified namespace for the schema
- fields: Array of field definitions with names and types
- connect.name: The Kafka Connect-specific schema identifier
AVRO schemas are the most common format for CDC data in Streamkap. They provide rich type information and support schema evolution with compatibility rules.Understanding Schema Subjects
Schema subjects organize schemas in the registry by their purpose and data structure.Subject Naming Conventions
CDC Source Schemas:source_67d010f15ad5681e912ccc5b.ecommerce2.Customers-key: Key schema for Customers tablesource_67d010f15ad5681e912ccc5b.ecommerce2.Customers-value: Value schema for Customers table
Key vs Value Schemas
Key Schemas:- Define the structure of message keys
- Typically contain primary key fields from source tables
- Used for partitioning and compaction
- Define the structure of message payloads
- Contain the full record data from source tables
- Include metadata fields like timestamps and operations
Schema Versioning
Schema Registry maintains a version history for each subject, enabling schema evolution tracking.Version Numbers
- Version 1: The initial schema registered for this subject
- Version 2+: Subsequent schema updates
- Latest: Alias for the most recent version
Schema Evolution
When schemas evolve, new versions are created. Common evolution scenarios: Backward Compatible Changes:- Adding fields with defaults
- Removing optional fields
- Adding fields
- Removing fields with defaults
- Adding optional fields with defaults (both backward and forward compatible)
Schema Types
Streamkap supports multiple schema serialization formats:In almost all cases, the source connector determines which schema serialization format is used.
AVRO
Most common for CDC workloads, especially from relational, structured sources Advantages:- Compact binary format
- Rich type system with logical types
- Strong schema evolution support
- Excellent compression
- Fast serialization/deserialization
- CDC data from relational databases
- High-throughput data pipelines
- Data warehousing workflows
JSON Schema
Human-readable text format, typically used with semi-structured sources Advantages:- Easy to read and debug
- Wide tooling support
- Flexible schema definitions
- REST API integrations
- Semi-structured data
- Developer-friendly debugging
Protocol Buffers (Protobuf)
Google’s binary serialization format Advantages:- Compact binary format
- Strong typing
- Code generation support
- Cross-language compatibility
- Microservices communication
- gRPC integrations
- Cross-platform data exchange
Working with Schemas
Copying Schema Definitions
To copy a schema for external use:- Navigate to the schema detail page
- Select the desired version from the dropdown
- Click the Copy Schema button
- The entire schema JSON will be copied to your clipboard
- Paste into your development tools, documentation, or schema management systems
Inspecting Schema Changes
To compare schema versions:- Open the schema detail page
- Note the current schema structure
- Use the version dropdown to select an earlier version
- Compare the field definitions, types, and structure
- Identify additions, removals, or type changes
Understanding Schema References
Schemas withHas References: Yes depend on other schema definitions:
- The schema imports types from other schemas
- Changes to referenced schemas may affect this schema
- Check referenced schemas for their definitions and versions
Schema Registry Best Practices
- Plan Schema Changes: Design schemas with future evolution in mind
- Test Compatibility: Validate schema changes against existing consumers before deployment
- Document Changes: Maintain a changelog of schema modifications
- Use Optional Fields: Make new fields optional with defaults for backward compatibility
- Avoid Breaking Changes: Never remove required fields or change field types
- Monitor Versions: Keep track of which schema versions are in use by consumers
- Clean Up Unused Schemas: Remove schemas for decommissioned topics or connectors
Schema Compatibility Modes
Schema Registry enforces compatibility rules to prevent breaking changes:BACKWARD (Default)
- Consumers using new schema can read data written with old schema
- Safe to add fields with defaults
- Safe to remove fields
FORWARD
- Consumers using old schema can read data written with new schema
- Safe to add fields
- Safe to remove fields with defaults
FULL
- Both backward and forward compatible
- Safest option for schema evolution
- Most restrictive
NONE
- No compatibility checking
- Use with caution
- Risk of consumer failures
Streamkap typically uses
BACKWARD compatibility mode for CDC schemas, allowing safe addition of columns in source databases.Troubleshooting
Schema Not Appearing
If a schema is missing from the registry:- Check Topic Activity: Schemas are registered on first message write
- Verify Connector: Ensure the source or destination connector is running
- Refresh the Page: Click refresh or reload the browser
- Check Project: Verify you’re viewing the correct Streamkap project
Schema Registration Failures
If schemas fail to register:- Review Connector Logs: Check for schema-related errors (Logs)
- Validate Schema Format: Ensure the schema is valid
AVRO|JSON|Protobuf - Check Compatibility: Verify the new schema is compatible with existing versions
- Check Registry Permissions: Ensure the connector has schema registry permissions
Version Mismatch
If consumers report schema version mismatches:- Check Consumer Configuration: Verify schema registry URL is correct
- Review Global IDs: Ensure consumers are requesting the correct global ID
- Update Consumers: Redeploy consumers with the latest schema version
- Validate Subject Names: Confirm consumers are using the correct subject name
Schema Evolution Errors
If schema evolution causes errors:- Review Compatibility Mode: Check the compatibility setting for the subject
- Identify Breaking Changes: Compare old and new schema versions
- Rollback if Needed: Revert to a previous schema version if consumers fail
- Update Consumers: Deploy consumer updates to handle new schema structure
Related Documentation
- Topics - Kafka topics that use schemas for serialization
- Sources - Source connectors that register schemas
- Destinations - Destination connectors that consume schema-encoded data
- Schema Evolution Support - How Streamkap handles schema changes
- Kafka Access - Configure permissions for schema registry access
- Logs - Troubleshoot schema-related errors